


AI Adoption ROI: Cheap Models, Expensive Illusions
Nov 19, 2025
Strip the glow off it. AI adoption ROI isn’t a vibe; it’s math dragged through operations. Right now, too many boards are measuring “AI success” in press releases and pilot counts while the invoice piles up backstage. Cheap-and-good models are real—especially open source and the new wave coming out of China—but the illusion is that “cheap” equals “ROI.” It doesn’t. The spread between model price and business value gets eaten by integration, reliability, guardrails, and the human rework no one budgets for. I’m not here to sneer at hope. I’m here to give you a checklist so you stop paying tuition to hype and start paying wages to results.
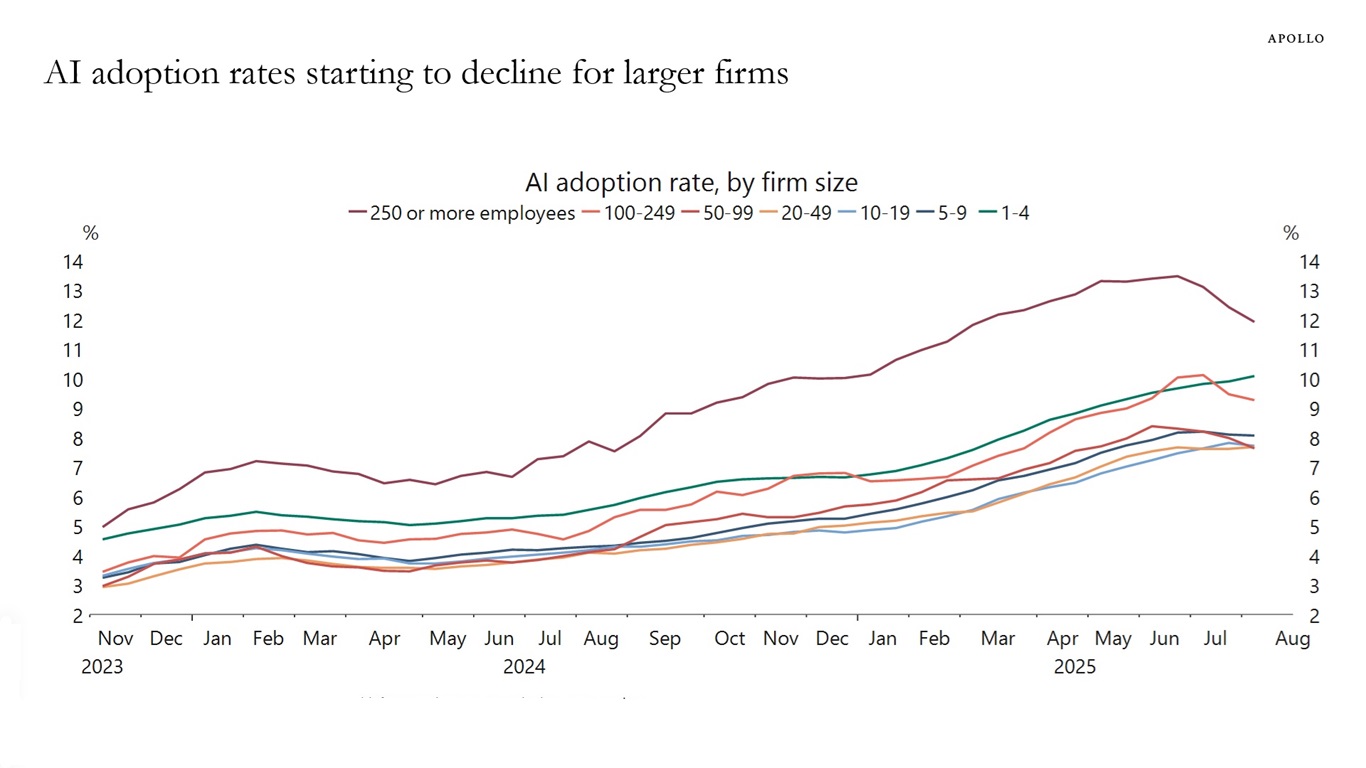
2023: Hype ignition. Frontier models sprint; pilots bloom everywhere. Scarce MLE and infra talent hides operational costs under heroics. Everyone promises “productivity unlocks.”
2024: Open source jumps a weight class; mixture-of-experts (MoE) designs cut compute per token. Price/performance curves bend. Check-writing gets easier; proof-of-value doesn’t.
H1 2025: Adoption hits the ROI wall. Majors quietly trim spend. Cheap-and-good models expand in Africa/Asia/LatAm through regional clouds. Rate limits and licensing soften outside the West. Procurement wakes up to cost ceilings and SLAs.
2025–2026: Consolidation. Model margins compress; workflow and data moats matter more than parameter counts. Regulations sharpen on privacy, sovereignty, and provenance. The story gets less pretty. The math gets honest.
Write it down or keep losing money. Inference gross margin = price per 1,000 tokens − (GPU amortization + energy + cooling + networking + orchestration + security/guardrails + human review/retry). Two killers: average utilization and error/retry tax. Peak charts brag; averages pay the power bill. Sub‑50% average utilization will implode ROI, no matter how “cheap” the model looks. And every hallucination, tool failure, or refusal that forces a retry adds 15–40% to cost unless you fund evaluation and guardrails properly. Don’t love the sentence. Obey it.
The operationalization tax you forgot to budget
AI doesn’t become ROI in a slide; it becomes ROI when the messy human system around it stops bleeding. Here’s the tax most teams skip:
• Evaluation harnesses: gold datasets, continuous tests, regression alerts. Without them, you’re flying on faith.
• Prompt ops: versioning, prompts-as-code, audit trails. Fixes must be repeatable, not heroic.
• Guardrails: PII/PHI redaction, policy enforcement, refusal handling, jailbreak resistance. Yes, you need an L4 or rules engine.
• Retrieval: grounding that actually grounds. Latency budgets and cache strategy, not aspirational diagrams.
• Human-in-the-loop: QA, spot checks, relabeling, and the authority to halt a bad rollout. That last part matters.
• Incident runbooks: latency spikes, model drift, provider outage, cost blowout. If you can’t answer “what fails open/closed?” you don’t have production—you have a live demo.
Open and low-cost models are not toys anymore. Many are good enough for 70–90% of enterprise tasks when paired with retrieval and guardrails. They slash per-token costs and loosen rate limits, which pressures Western pricing power. But “cheap” is not a moat if your workflows are sloppy, your data is dirty, or your team treats prompts like magic spells. Cheap models amplify skill or incompetence—whichever you bring to the table.
AI adoption ROI: build a weekly watchlist
Stop arguing about vibes and track the receipts:
• GPU rental curves: spot and term rates for current accelerators vs your financing cost; falling curves without demand rising = margin squeeze ahead.
• Used accelerator prices and time-to-sale: discounting is demand fatigue in plain clothes.
• Inference price per 1K tokens: what you pay across vendors and open alternatives (including egress/ingress). Price compression without usage growth bites hard.
• Reliability/SLA incidents: vendor status pages and your own SLOs; P95 and P99 latency under load tell you more than a keynote ever will.
• Utilization: average, not peak; per-service concurrency; off-peak drop-off. Means over metaphors.
• Power/permits: substation timelines, interconnect queues, cooling lead times. No megawatts, no model.
• Vendor unit margins: are they rising, flat, or falling as revenue grows? Growth without margin is theater.
Three scenarios, with if–then you can trade and execute
Soft landing: Eval harnesses mature; guardrails cut error tax; usage climbs while prices compress moderately. Then: accumulate the boring toolchain (observability, eval, policy/guardrail platforms) with real revenue. Own providers with improving gross margins and sticky enterprise data. Avoid “platform” stories that can’t show margin discipline.
Margin crunch: Customers churn to cheap-and-good; per-token prices drop sharply; ROI stalls; spend gets trimmed. Then: underweight high-burn “platforms” with vague moats; overweight infra that invoices in cash—networking, power, cooling. Trade open-source ecosystem winners. Keep a cluster-buy plan for quality semis/gear after a 20–30% reset with signs of margin stabilization.
Open-source shock: A free/cheap model matches frontier for common enterprise tasks; regulators tolerate the stack. Then: buy workflow and data-layer vendors; sell pure-model premiums that can’t defend with distribution, compliance, or vertical product. Accumulate services with repeatable implementation playbooks and audited savings.
Buyer’s diligence checklist (so pilots graduate to profit)
• Data: residency, retention, model-training rights, encryption (at rest/in transit), privacy posture. No ambiguity in contracts.
• Evaluation: gold sets; regression protocol; pass/fail thresholds tied to cost ceilings. Measure before you brag.
• Latency: P95/P99 under real load; degradation rules; fallback (cached answers, smaller models, non-LLM path). Decide fail open/closed now.
• Cost: ceiling per task or per 1K tokens; burst pricing; rate limits; exit math to swap providers. No golden handcuffs without a ransom plan.
• Observability: token-level tracing, prompt/version control, full audit logs by user/task.
• Security/PII: redaction, classification, abuse prevention, incident history transparency.
Pause fresh AI longs until the tape breathes. Green lights you can trust: sector drawdown of 15–25% and at least two of: used GPU prices stabilizing; rental curves flattening; platform gross margins stopping their slide for a full quarter. Then deploy a cluster buy in quarters: 1/4 per green light across your shortlist (e.g., semis, equipment, comms silicon), never compress all buys into one week. Pre-write trims: parabolic weekly moves and euphoric tape get 10–25% peeled; reload after 8–15% cool-offs and improving unit margins. It’s a metronome, not a performance.
Execution hygiene (this pays more than cleverness)
Two windows: mid‑morning and mid‑afternoon—avoid the edges where headlines ambush. Rule‑of‑Three: act only when three independent receipts align (for example: rental curves flatten, used prices stabilize, vendor margins stop bleeding). Emotion gate: before any order, rate your state 1–5; above 3—fear, FOMO, shame—pause 90 seconds, breathe 4‑4‑4‑4, halve size or pass. Orders‑only on mega‑event days; trade the plan you wrote yesterday, not the feed you scrolled five minutes ago. And the recognition tax: if you need an audience to press buy, don’t.
You run customer support. Baseline: 450 agents, 3-minute average handle time, $X/month. Pilot a retrieval‑grounded assistant with a modest model. Before rollout, you build a 1,000‑case gold set, define “good” as accuracy ≥95% on critical intents, and set a cost ceiling of $0.15/1K tokens all-in. You measure P95 latency, require fallback to a deterministic flow if latency >1.5s or confidence < threshold. You stage rollout: 10% traffic, then 33%, then 66%, with guardrails tight. Weekly review shows handle time −18%, escalations −12%, cost +$0.04/contact, CSAT flat to up. You bank the savings and use half to fund better eval harnesses. That’s AI adoption ROI. Not a deck. A ledger.
What fails most pilots (so you can un‑fail them)
• Goals written as adjectives (“delight,” “transform”) not verbs with metrics.
• No eval harness—shipping on vibes, panicking on regressions.
• “One big model” worship; wrong model for the job; no routing or caching discipline.
• No fallback; outages turn into headlines.
• Cost telemetry missing; finance hears about the bill from a journalist.
• Security theater; privacy posture collapses under the first audit.
Close: measure the work, not the worship
AI adoption ROI is cruel and fair. It pays the teams that treat models like engines inside workflows, not miracles inside slides. It punishes FOMO, sloppy ops, and price tags mistaken for moats. Cheap models will keep getting better; expensive illusions will keep getting louder. Your edge is boring: unit economics on paper, operationalization funded, a weekly watchlist, and rules you’ll obey on a bad day. Trim when the choir sings. Add when the receipts line up. Don’t buy applause. Buy outcomes. And if you need one sentence to keep you honest: clever gets harvested; process gets paid.







